
Data Engineering Roadmap

I know how hard it is to search for a job. I personally had to apply to over 3000 jobs to get an internship and full time job. And this is exactly why, I provide all my resources and information for free. and I hope that even 1% of this can help you in your career. At the same time, I do this all by myself and don’t have anyone to help or any marketing budget to work with. So, if you find this article helpful, consider supporting me by making a donation through buymeacoffee , becoming a paid member of substack or subscribing to my Youtube page.
DATA ENGINEERING ROADMAP :
100+ SQL Interview Questions:
Here is the complete excel sheet of over 300+ questions for SQL which will help you ace any interview : Link.
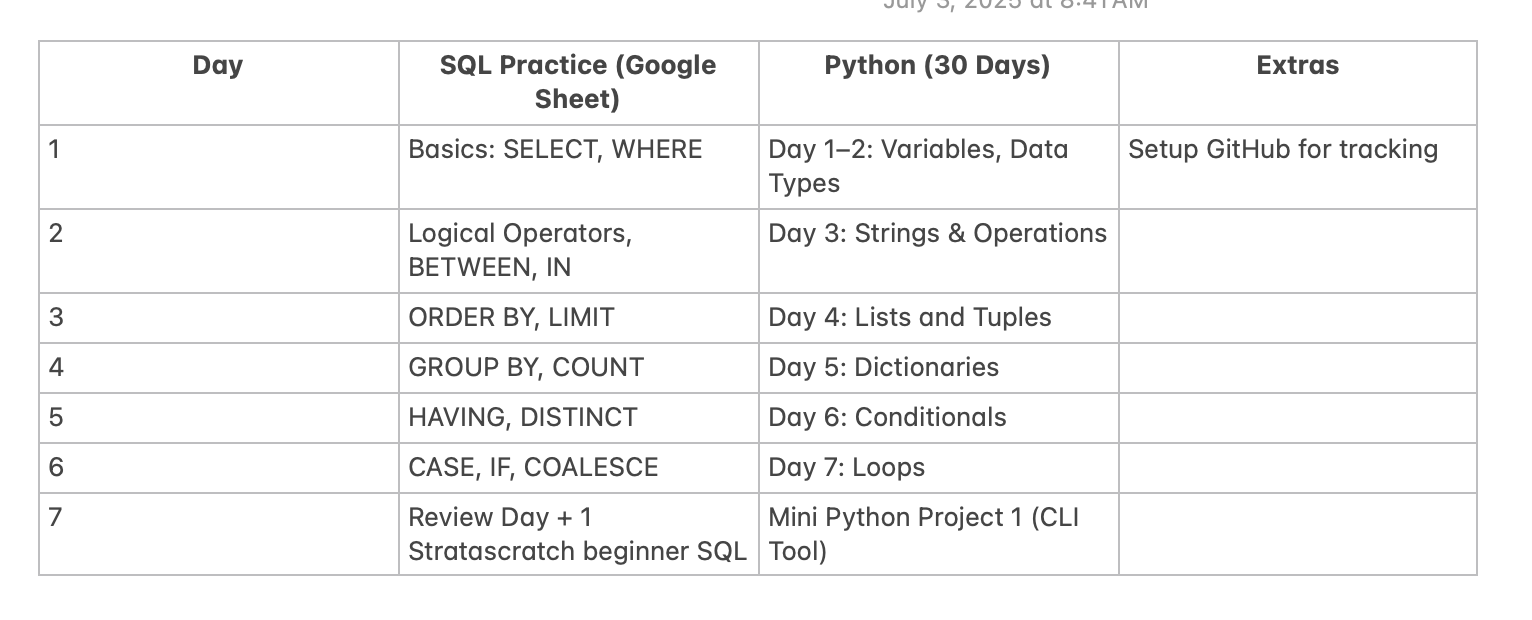
Even practice one question a day will help you master your skills.
SQL Theory Questions
For SQL Theory Questions, I used this resource : Link which has 100+ SQL Theory questions and literally everything you need to prepare for your interview. Use this and you will be set for life in SQL Theory questions.
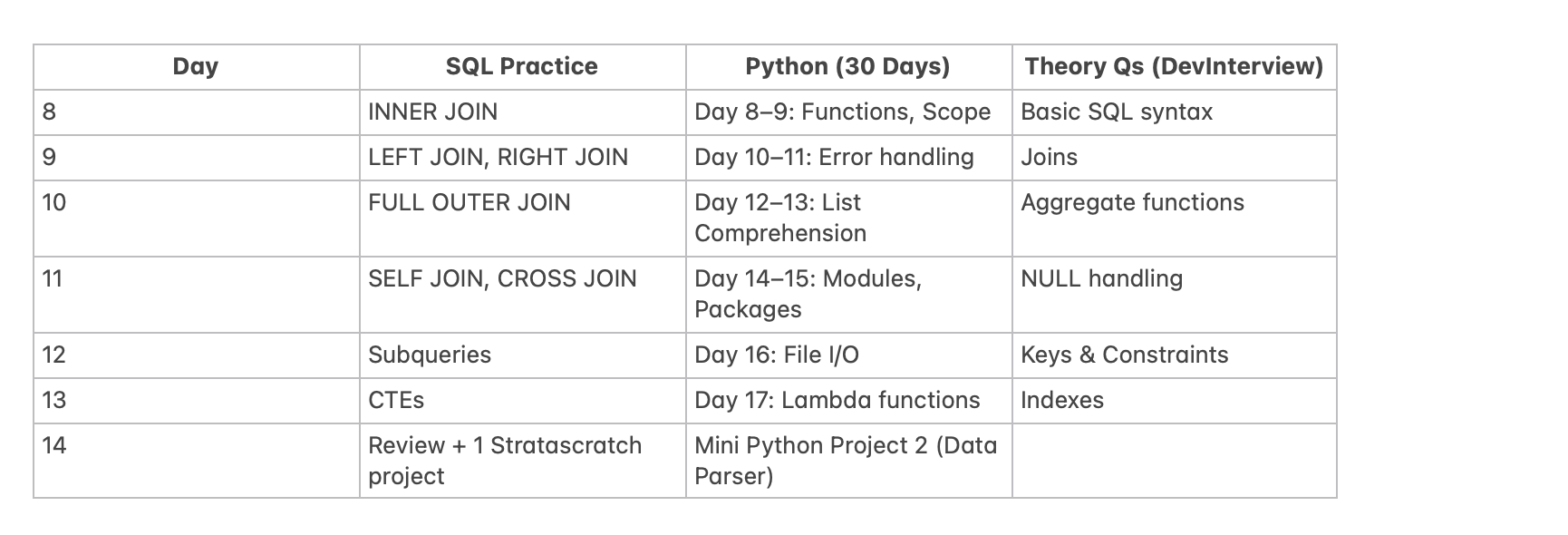
Learning and Practicing Python :
For learning Python, I used the 30 days of Python to learn the concepts: Link
And this was done with stratetgic usage of Leetcode questions. For complex topics like dynamic programming , trees, etc, I practiced easy questions and focussed on strengthening the concepts. And here was the prep
I used the projects from this link to practice Python : Link
Python coding Prep : Link
ROADMAP :


Kubernetes CheatSheet : Link
AWS CheatSheet : Link
Docker Cheatsheet : Link
Docker Interview Questions : Link
Kubernetes Interview Questions : Link
For system design Interview Questions, I used grokking the modern system design course. : Link
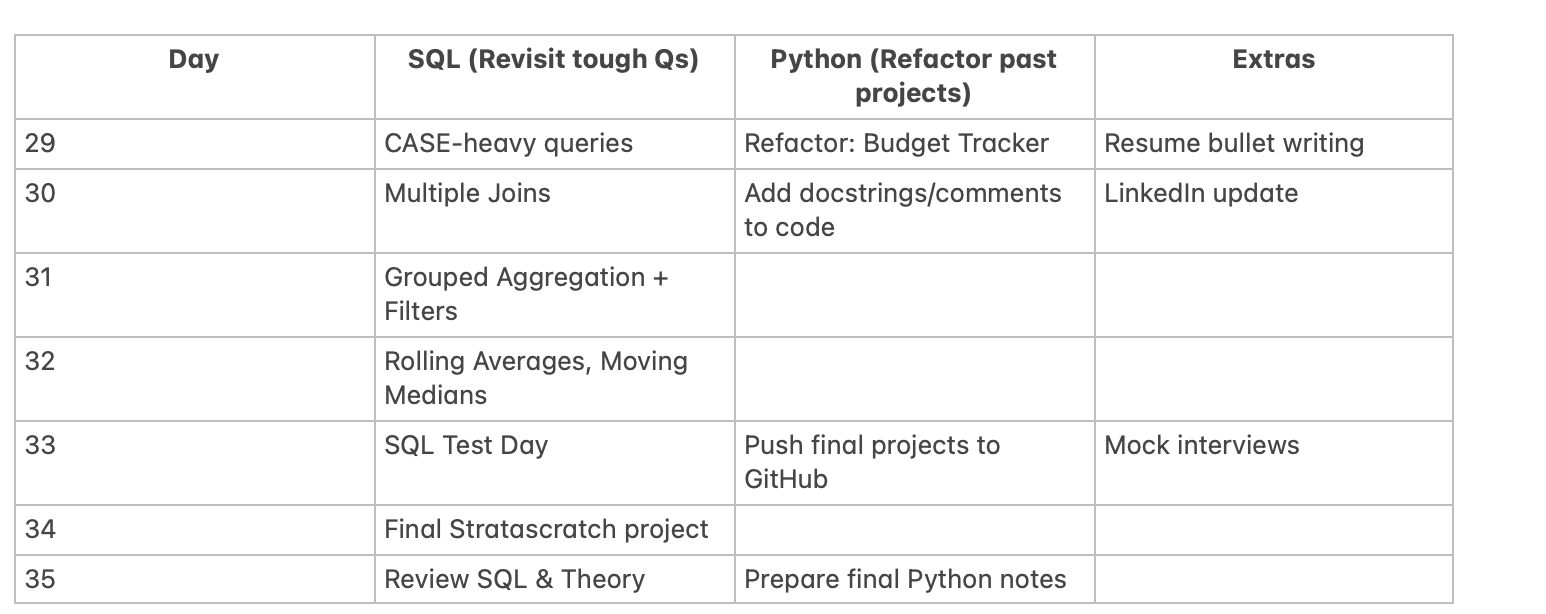
Data Engineering Projects I practiced :
Real estate dagster pipeline: A practical data engineering project for processing real estate data. Accompanied by a blog article: Building a Data Engineering Project in 20 Minutes.
Open Data Stack Projects: Examples of end-to-end data engineering projects using the Open Data Stack (e.g. dbt, Airbyte, Dagster, Metabase/Rill).
Airbyte Monitoring with dbt and Metabase: Monitoring Airbyte with dbt and Metabase. GitHub Code
«Open Enterprise Data Platform»: Integrates the prowess of open-source tools into a unified, enterprise-grade data platform. It simplifies end-to-end data engineering by converging tools like dbt, Airflow, and Superset, anchored on a robust Postgres database.
Example Pipeline with Airflow
KubernetesPodOperatorand dbt: Downloads ~150 CSVs, inserts into Postgres, and runs dbt. Everything is runnable with Astro CLI. A good example of how to use KubernetesPodOperator locally and in production.Data engineering Kestra example with dlt and Snowflake: Learn to build enterprise data pipelines using Kestra orchestrator, dlt, and Snowflake. Covers secrets management, git sync, and AI integration.
More projects : Link
Credits to source : Link
ROADMAP
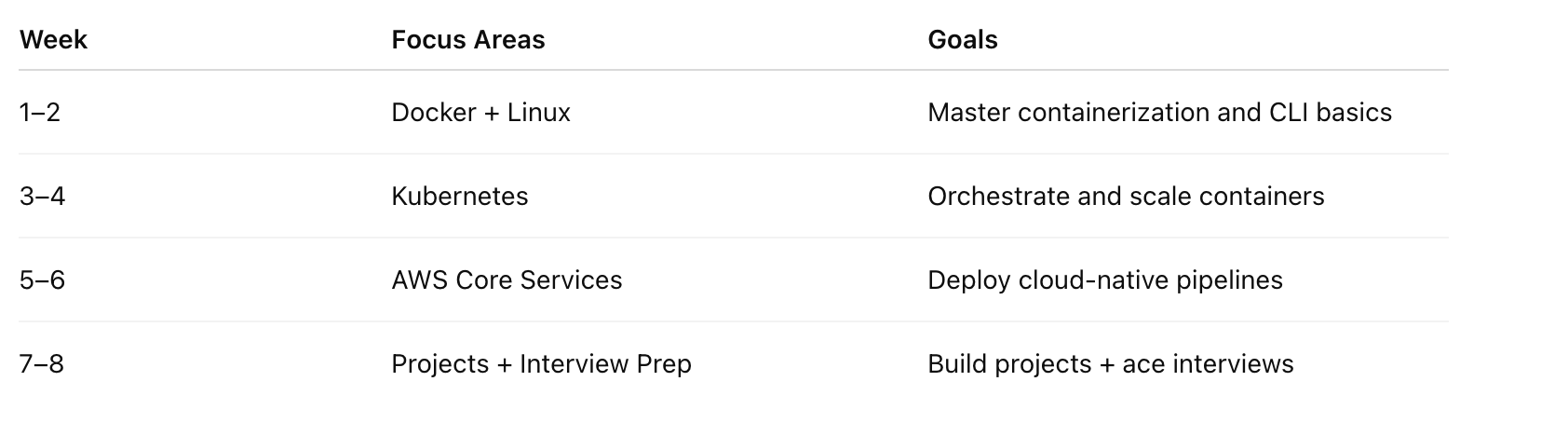
60 Day Daily Plan for Rest of the Technologies (High-Level)
📍Week 1–2: Docker + Linux Basics
Goals: Understand containerization, images, volumes, and basic shell commands.
Day 1–2:
Install Docker
Explore the Docker Cheatsheet
Learn Docker CLI:
run,build,exec,volume,networkPractice Dockerfile creation
Day 3–4:
Use multi-stage builds
Understand
docker-composeCreate a containerized Flask or FastAPI app with Postgres
Day 5:
Learn Linux commands (
ls,grep,awk,sed,crontab, permissions)Use Docker containers to practice Linux commands
Day 6–7:
Solve 5–10 Docker Interview Questions
Mini-Project: Build and deploy a containerized ETL job
📍Week 3–4: Kubernetes
Goals: Orchestrate, scale, and manage containers in clusters.
Day 8–9:
Learn Kubernetes CheatSheet:
pods,services,deployments,replicasetsUse
minikubeorkindfor local practice
Day 10–11:
Deploy a multi-container app using
kubectlUnderstand YAML configs and rolling updates
Day 12–13:
Learn about
ConfigMaps,Secrets,Ingress,Volumes, andHelmbasics
Day 14:
Review 5–10 Kubernetes Interview Questions
Mini-Project: Deploy containerized ETL + API via Kubernetes
📍Week 5–6: AWS Cloud Services
Goals: Understand and use AWS for scalable, cloud-based data pipelines.
Day 15–16:
Study AWS CheatSheet: IAM, EC2, S3, VPC
Launch EC2 and set up secure access
Day 17–18:
Use S3 for data storage
Understand lifecycle policies and security
Day 19–20:
Learn Lambda + EventBridge basics
Trigger serverless jobs
Day 21:
Learn RDS + Glue basics
Mock Interview: AWS + Docker
📍Week 7–8: Data Engineering Projects + Interview Prep
Goals: Build real-world pipelines + practice for interviews
Day 22–28:
Project 1:
Use Docker to containerize
Deploy on Kubernetes
Store logs/data in S3
Optional: Trigger Lambda alerts
Day 29–35:
Project 2:
Batch processing pipeline with Apache Airflow (on Docker)
Data in S3 → processed → stored in RDS
Hosted via Kubernetes or EC2
Day 36–42:
Solve 10+ questions from each interview guide
Practice explaining your projects
Add projects to GitHub with README
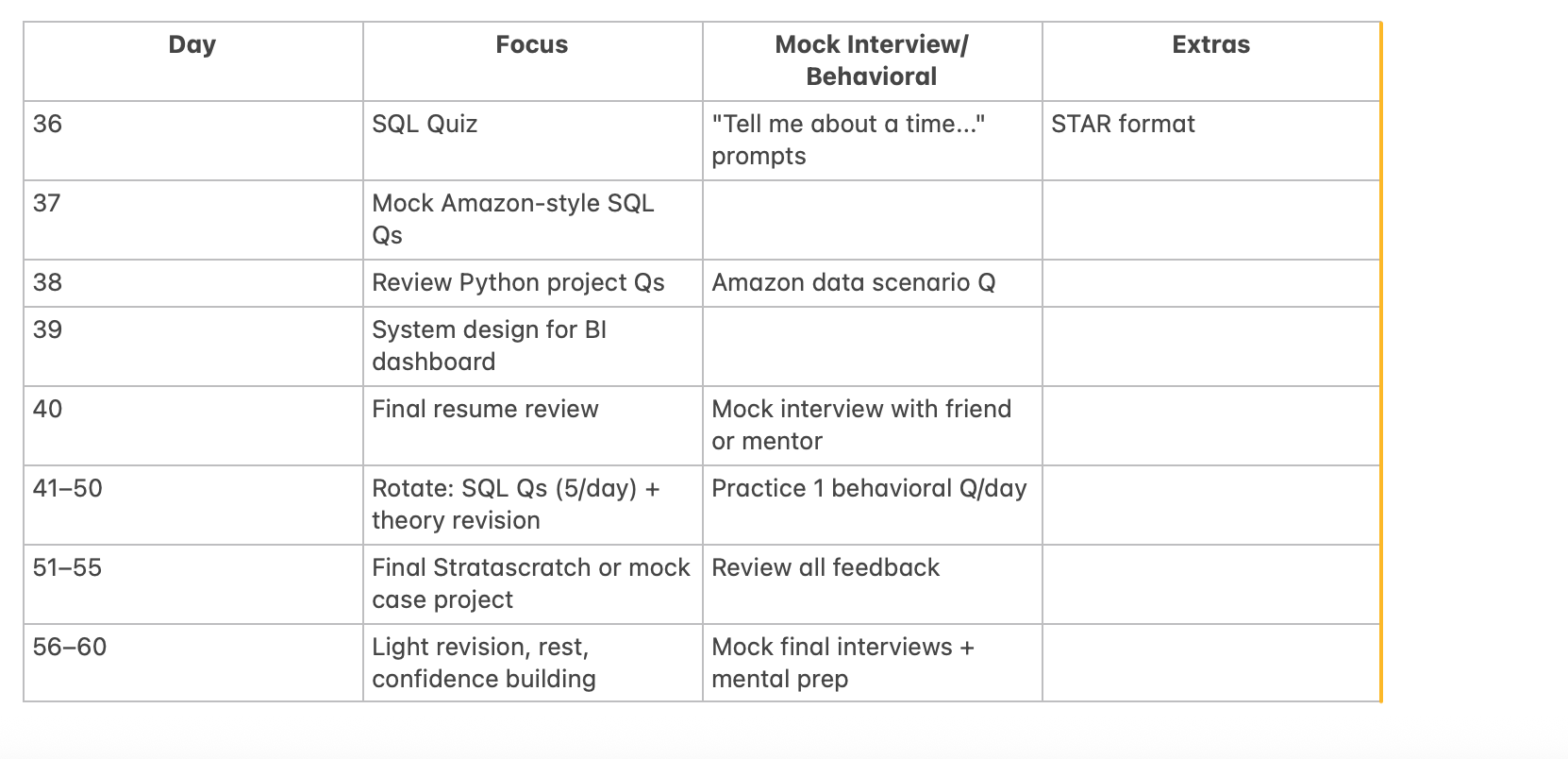
🧠 Final 2 Weeks: System Design + Mock Interviews
Goals: Understand scalability, fault tolerance, and data architecture
Day 43–49:
Study Grokking Modern System Design (Link)
Focus on:
Data ingestion at scale
ETL system design
Scalable logging systems
Data lake vs warehouse
Practice drawing diagrams
Day 50–56:
Mock system design interview with self/peer
Practice:
Tradeoffs (cost vs latency)
High availability
Fault tolerance
Wrap-Up (Day 57–60)
Polish LinkedIn + GitHub
Final resume pass with keywords (Docker, K8s, AWS, ETL, System Design)
Final mocks:
1 Behavioral
1 Technical (K8s/AWS)
1 System Design